您现在的位置::首页 > 资讯管理 > 厂商要闻 > 新品扫描
8月26日消息 继6月份的麒麟810芯片后,华为达芬奇架构NPU在上周又一次迎来重磅消息,被集合到了号称业内算力*强的AI芯片——Ascend 910(昇腾910)上。
与此同时,华为还推出了与Ascend 910相配套的深度学计算框架MindSpore。按华为轮值董事长徐直军的话说,Ascend 910、MindSpore的推出,标志着华为已完成全栈全场景AI解决方案的构建,也标志着华为AI战略的执行进入了新阶段。
2018年华为全联接大会上,Ascend 910和Ascend 310首次亮相,达芬奇架构也首次被运用在宣布商用的Ascend 310上。
华为表示,设计达芬奇架构的初衷,是为了应对万物智能互联的新时代,实现AI在多平台多场景之间的协同。
数据预测,到2025年全球智能终端数量将会达到400亿台,智能助理的普及率将达到90%,企业数据的使用率将达到86%。在不久的将来,AI将作为一项通用技术极大地提高生产力,改变每个组织和每个行业。
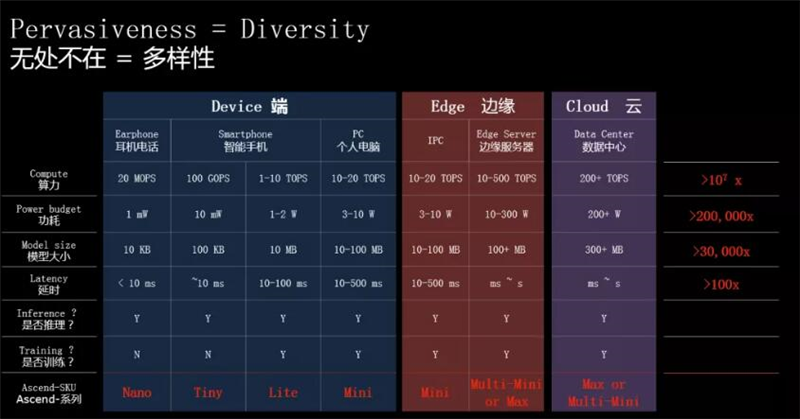
这一趋势,促使了华为全栈全场景AI战略在2018全联接大会上的提出。而达芬奇架构,正是华为的面向AI计算特征的全新计算架构,具备高算力、高能效、灵活可裁剪的特性,是其实现万物智能的重要基础。
基于灵活可扩展的特性,达芬奇架构能够满足端侧、边缘侧及云端的应用场景,可用于小到几十毫瓦,大到几百瓦的训练场景,横跨全场景提供*算力。
以Ascend芯片为例,Ascend-Nano可以用于耳机等IoT设备的使用场景;Ascend-Tiny和Ascend-Lite用于智能手机的AI运算处理;在笔记本电脑等算力需求更高的便携设备上,由Ascend-Mini提供算力支持;而边缘侧服务器上则需要由Multi-Ascend 310完成AI计算;至于复杂的云端数据运算处理,则交由算力*可达256 TFLOPS@FP16的Ascend-Max来完成。
基于达芬奇架构的统一性,开发者在面对云端、边缘侧、端侧等全场景应用开发时,只需要进行一次算子开发和调试,就可以应用于不同平台。

关注本网官方微信公众号 随时阅读专业资讯

征稿邮箱:info@testmart.cn 
版权与免责声明
爆品推荐
会员服务热线:010-62681193
展会合作/友情链接:010-62681114







 京公网安备 11010802023672号
京公网安备 11010802023672号
网友推荐新闻: